
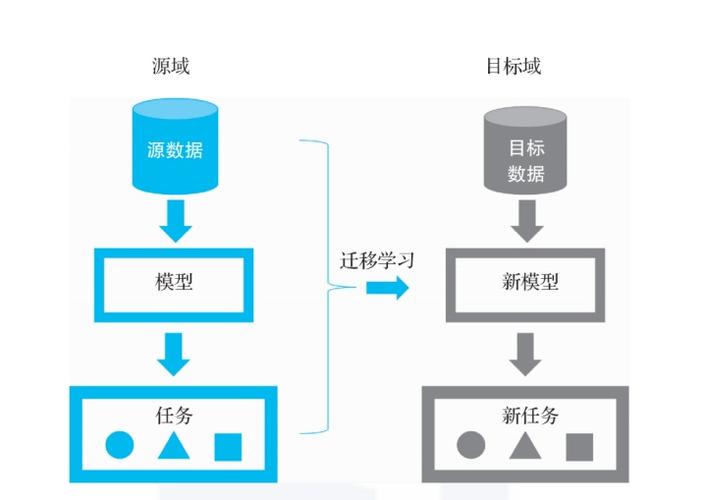
NeurIPS2022|如何实现表格数据上的迁移学习和零样本学习。
本年的 NeurIPS 评分7/7/7 有惊无险中了一篇文章,做的是在表格数据上的pretraining, transfer learning,和 zero-shot learning。
论文链接: https://arxiv.org/pdf/2205.09328.pdf 代码链接: https://github.com/RyanWangZf/transtab 文档链接: https://transtab.readthedocs.io/en/latest/
一、 不够flexible的表格进修
表格进修(tabular learning)顾名思义也便是在表格上的进修(废话)。比喻说,许多 kaggle 上的竞赛都是属于表格进修的领域,都是构建多少个 feature,然后猜测对应的标签。
可以说比起 CV 和 NLP,tabular learning 才是实际天下中机械进修会更常常用到的场景。
在 CV,NLP 范畴通常有一个通用的输入(CV:由像素构成的图片;NLP:由词或者 token 构成的文本),然则 tabular learning(表格进修)范畴的模子每每限制在统一个设定的表格。导致已经学好的模子只能在统一个表格上猜测。
年夜家都知道比来在 NLP 和 CV 范畴各类预训练模子年夜杀四方,属于深度进修办法的 BERT,ViT 之流都已经成了标配的 backbone。然则,在表格范畴每每照样 “xgboost is all you need”。无他,简单直接好用,后果还不差。在这种环境下,天然就有了不少研讨者把眼光投到了这片传统机械进修的“末了的碉堡”。
比来的办法,好比 VIME [1],SCARF [2],SubTab [3] 等都把自监视进修引入了表格范畴,或是做一些 masked cell modeling(感觉上便是 auto-encoder 的变种),或是做一些 contrastive learning 把一行的 feature 做一些替换,删除之类的操作来构建正负样本。
然则,他们的设建都不年夜相符真实场景。我们每每不是说有一个伟大的表格,然后只有此中一点点样本有标签。而是说我们有多少个有标签的表格,然则每个表格的列名(column)都不年夜一样。问题在于怎样把这些表格都应用起来,进修一个年夜模子,能力最年夜水平地应用手上的数据。
然则,已知的所有办法都只能处置固定 column 的表格。一旦表格的 column 有一丝丝变化,好比 age->ages,或者 age 这一列被删失落。那么之前训练好的模子就没用了,只能从新 数据处置->特性工程->模子训练 这一个流程。这无疑是晦气于我们实现像 CV 和 NLP 里那样做表格进修的年夜模子训练的。
那么,有没有一种可能,我们设计一种模子,不管表格酿成啥样,都能进行编码和猜测呢。
二、足够flexible的表格进修
事实上,假如我们细心察看每一个表格,会发现实在表格的列名(column names)实在蕴含了丰硕的信息。好比在上图中,age 列对应了 25,我们天然就知道是 25 岁;income 列对应了 10000,我们知道可能是 10000 个某种泉币单元。假如 age 列改成 weight,25 就不再表现 25 岁,而是 25kg 或者其它重量单元。由此可见,表格中 feature 所代表的语义信息是由 column 所决议的。假如我们想要迁徙表格的信息,则必需要斟酌到 column 的语义。
上表有三种 feature,分离是 gender (种别型),age(数值型),和 is_grduated(布尔型)。
对付三种类型的 feature,我们可作分歧的处置。
对付种别型(categorical),我们直接把列名与其拼在一路,“male” 变为 “gender male”;
对付数值型(numerical),我们先把列名 tokenize 和 embedding,再把数值 和 embedding 作 element-wise 相乘;
对付布尔型(boolean),我们把列名 tokenize 和embedding,再依据 feature 是 1 或者 0 来决议是否保存此 embedding。假如是 1,则直接保存;是 0 则不将此 feature 参加之后的 embedding;
对应下图的特性处置模块。
TransTab的特性处置模块
有了这个处置模块,理论上随意率性 column 的表格,TransTab 都可以将其处置成 embedding,作为后续 transformers 的输入进行处置和猜测。
三、TransTab能做什么
由于可以编码随意率性的表格数据,TransTab 可以支撑以下一些新义务:
在多个表格上直接进行 supervised learning,然后做 finetuning
在来自统一个范畴然则 feature 分歧的表格上一路 supervised learning
在多个范畴有或无标签的表格上做 contrastive pretraining
在多个表格上 supervised learning 后在一个新的表格上直接做猜测
对应下图的(1)-(4)项义务。
TransTab支撑的tabular learning义务。
四、TransTab的预训练
下面我们再简单讲一下怎样基于 TransTab 做预训练。我们的设定如上图(3)所示,假定我们有一系列上游表格,它们有可能有标签或者没标签。我们在有标签的数据上更愿望能应用到标签信息,那么可能的设法主意是:对付所有表格共享一个 backbone,然后对每一个表格零丁设置一个 classification head 做 supervised learning。
在多个表格上共享 backbone,零丁设置 head 的方式不容易进修
然则我们发现,如许做会导致 backbone encoder 很难学到好的表征。由于每个表格的标签种别分歧,或者可能是相反的界说(好比 mortality 和 survival)。斟酌到这点,我们引入了一种基于标签的 supervised contrastive learning,在论文里叫做 vertical partition contrastive learning(VPCL)。
论文中提出的 supervised vertical partition contrastive learning(VPCL)。每一个样本按列分成多少个 partition,来自统一个种别的 partition 互为正样本。
试验发现,这种 supervised CL 得到更好的预训练模子。
五、TransTab表示若何
接下来便是枯燥的试验环节啦。篇幅所限,只展现一小部门,更多的请参考论文。
5.1 预训练
TransTab预训练试验成果
左边是在多个临床实验数据集长进行预训练和 finetune 之后的成果。与零丁在每个表格上训练的 baseline 相比,预训练带来了较年夜的均匀晋升。
右边是同样的试验,然则在一些公开表格数据长进行预训练和 finetune。由于公开数据来自多种范畴,异常分歧,我们看到 VPCL 照样升。
5.2 零样本猜测
TransTab零样本猜测成果
我们测验考试了在上游数据上 supervised learning 然后在下游表格上不训练直接猜测。上图的 x 轴是上下游表格列之间重合的比例。我们可以看到,在上下游表格没有任何重合的环境下,TransTab 仍旧能在多个表格上做出优于 random guess 的猜测(AUC 到达 0.55 左右)。这阐明了 TransTab 具有必定的零样本揣摸才能。
六、总结
总体来说,这篇文章的办法属于 simple and effective (高情商)。我们愿望可以或许让 deep learning 在表格范畴发光发烧,就必要施展 deep learning 做表征进修的才能。这篇文章初步摸索了做表格进修的迁徙和零样本猜测。之后可以更多地应用 language modeling 的办法,来晋升语义进修的才能,晋升迁徙才能和猜测才能。
参考文献
[1] Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela van der Schaar. VIME: Extending the success of self-and semi-supervised learning to tabular domain. Advances in Neural Information Processing Systems, 33:11033–11043, 2020.
[2] Dara Bahri, Heinrich Jiang, Yi Tay, and Donald Metzler. SCARF: Self-supervised contrastive learning using random feature corruption. In International Conference on Learning Representations, 2022.
[3] Talip Ucar, Ehsan Hajiramezanali, and Lindsay Edwards. SubTab: Subsetting features of tabular data for self-supervised representation learning. Advances in Neural Information Processing Systems, 34, 2021.
"大众号:【 PaperWeekly】 作者:Zifeng Wang
Illustration by Manypixels Gallery from IconScout
-The End-
扫码旁观。
本周上新。
关于我“门”
将门是一家以专注于挖掘、加快及投资技术驱动型创业公司的新型创谋利构,旗下涵盖将门立异服务、将门技术社群以及将门创投基金。
将门成立于2015岁尾,开创团队由微软创投在中国的开创团队原班人马构建而成,曾为微软优选和深度孵化了126家立异的技术型创业公司。
假如您是技术范畴的始创企业,不仅想得到投资,还愿望得到一系列连续性、有代价的投后服务,迎接发送或者保举项目给我“门”:
bp@thejiangmen.com
点击右上角,把文章分享到同伙圈
⤵一键送你进入TechBeat快活星球